python爬虫之图片下载APP 2.0
本文共 1586 字,大约阅读时间需要 5 分钟。
上次讲到利用python进行搜索并下载图片,今天更新一下,我们知道, 这个网站搜索图片需要英文,但有些人不太会使用英文,想搜索什么东西需要先去翻译了才能搜索,今天调用API store里面的斯必克API进行自动翻译,这样就可以输入中文进行搜索啦!
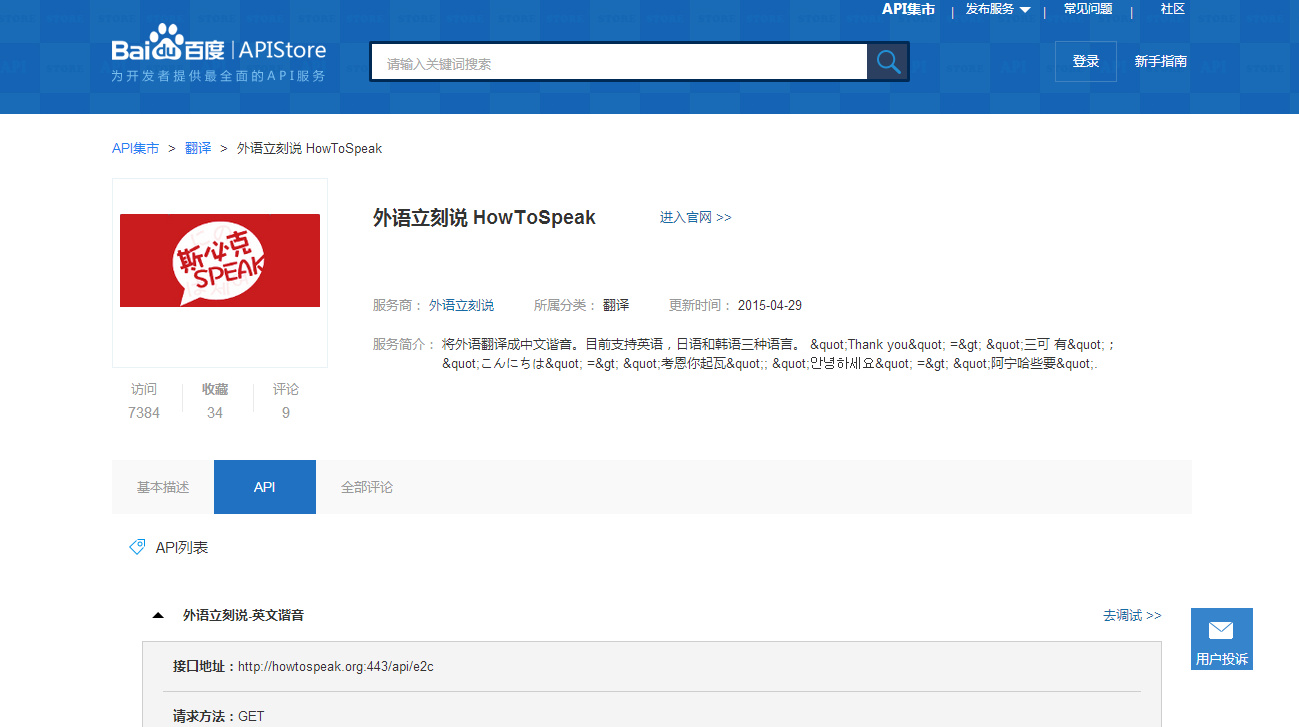
看修改的代码:
from bs4 import BeautifulSoupimport requestsimport jsonheaders ={ 'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Cookie':'__cfduid=dcb472bad94316522ad55151de6879acc1479632720; locale=en; _ga=GA1.2.1575445427.1479632759; _gat=1; _hjIncludedInSample=1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}url_path = 'https://www.pexels.com/search/'word= input('请输入你要下载的图片:')url_tra ='http://howtospeak.org:443/api/e2c?user_key=dfcacb6404295f9ed9e430f67b641a8e ¬rans=0&text=' + wordenglish_data = requests.get(url_tra)js_data = json.loads(english_data.text)content = js_data['english']url = url_path + content + '/'wb_data = requests.get(url,headers=headers)soup = BeautifulSoup(wb_data.text,'lxml')imgs = soup.select('a > img')list = []for img in imgs: photo = img.get('src') list.append(photo)path = 'C://Users/Administrator/Desktop/photo/'i = 1for item in list: if item==None: pass elif '?' in item: data = requests.get(item,headers=headers) fp = open(path+content+str(i)+'.jpeg','wb') fp.write(data.content) fp.close i = i+1 else: data = requests.get(item, headers=headers) fp = open(path+item[-10:],'wb') fp.write(data.content) fp.close() 总结
1 API的调用,现在许多API是json格式,我使用了json库进行解析,取我要的英语翻译构成网页
2 不足:可能会出现找不到网页的情况,因为搜索的网站构成不一样,如何智能匹配是以后需要考虑的。转载地址:http://kxrdx.baihongyu.com/
你可能感兴趣的文章
測試文章
查看>>
Flex很难?一文就足够了
查看>>
【BATJ面试必会】JAVA面试到底需要掌握什么?【上】
查看>>
CollabNet_Subversion小结
查看>>
mysql定时备份自动上传
查看>>
Linux 高可用集群解决方案
查看>>
17岁时少年决定把海洋洗干净,现在21岁的他做到了
查看>>
linux 启动oracle
查看>>
《写给大忙人看的java se 8》笔记
查看>>
倒计时:计算时间差
查看>>
Linux/windows P2V VMWare ESXi
查看>>
Windows XP倒计时到底意味着什么?
查看>>
tomcat一步步实现反向代理、负载均衡、内存复制
查看>>
运维工程师在干什么学些什么?【致菜鸟】
查看>>
Linux中iptables详解
查看>>
java中回调函数以及关于包装类的Demo
查看>>
maven异常:missing artifact jdk.tools:jar:1.6
查看>>
终端安全求生指南(五)-——日志管理
查看>>
Nginx 使用 openssl 的自签名证书
查看>>
创业维艰、守成不易
查看>>